Project Proposal
Table of Contents
In this project, we are trying to build a deep learning model for color transfer between images.
Early color transfer approaches change colors of a source image based on the global color distribution of a reference image. Some methods perform color transfer by matching the means and standard deviations of source to reference images while others explore color mapping between source and reference images leveraging probability density functions of colors. These conventional approaches, however, may fail to reflect semantic correspondence because they do not consider any spatial information. To handle the limitation of global color transfer, several approaches contemplate local correspondences between source and reference images. While these approaches solve the problem of global color transfer in the case that source and reference images have similar structures, they may fail when both images have totally irrelevant contents and styles.

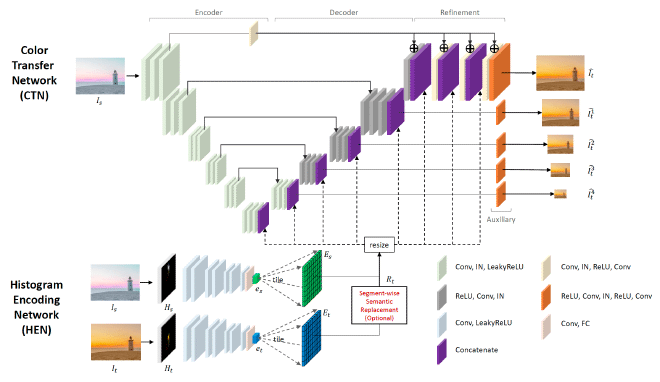
The authors of Deep Color Transfer Using Histogram Analogy [1] proposed a deep learning framework that leverages color histogram analogy for color transfer between source and reference images (Fig. 1). The framework consists of two networks, a Histogram Encoding Network (HEN) and a Color Transfer Network (CTN) (Fig. 2). HEN extracts encoded information from the histograms of source and reference images, which is fed into CTN to guide the color transfer process. Although a histogram is a simple and global representation of image colors, convolutional neural networks with encoded histograms can conditionally transfer the colors of reference images to source images. For strongly relevant and irrelevant cases, the same histogram information is used for all parts of the source image, and this is the default setting. When semantic object information is important, as in the case of weak relevance, semantic image segmentation is used and the histogram analogy is extracted and applied for corresponding semantic regions between source and reference images.
As the authors did in [1], we’ll train our model on a paired dataset constructed from the MIT-Adobe 5K dataset [2] which consists of six sets, each of which contains 5,000 images. In the dataset, the first set contains the original images and the other five sets contain color varied images of the original images retouched by five different experts. The paired dataset enables the model to learn to transfer color into natural-looking images. Since using the dataset only provides image pairs with a fixed number of combinations, we’ll also perform color augmentation by transforming the average hue and saturation of the original images to produce more diverse image pairs. In addition, as an ideally trained model must produce the output image the same as the source image if the histograms of the two images are the same, we’ll use identical source and reference image pairs to stabilize the network output.
The paper this project bases on was published in 2020 and it has been 2 years since that, during which many advanced vision models were proposed and have brought the scores of benchmarks to a new level. Beyond implementing the model mentioned in [1], we will try some SOTA semantic(or panoptic) segmentation methods to see if they could improve the performance in the case of weak relevance between the source image and the reference image. Image transformers like BEiT [3], Swin Transformers [4], and MaX-DeepLab [5] have drawn much attention recently, we will try to introduce transformers into the current framework and see if a better color transfer can be produced.